
Ranked: The Smartest AI Models of 2026
As the field of artificial intelligence continues to evolve rapidly, the competition among AI models has intensified. In April 2026, TrackingAI released its latest benchmark results from the Mensa Norway IQ test, revealing the smartest AI models currently available. This article explores the top contenders, their scores, and what these rankings mean for the future of AI.
Key Takeaways
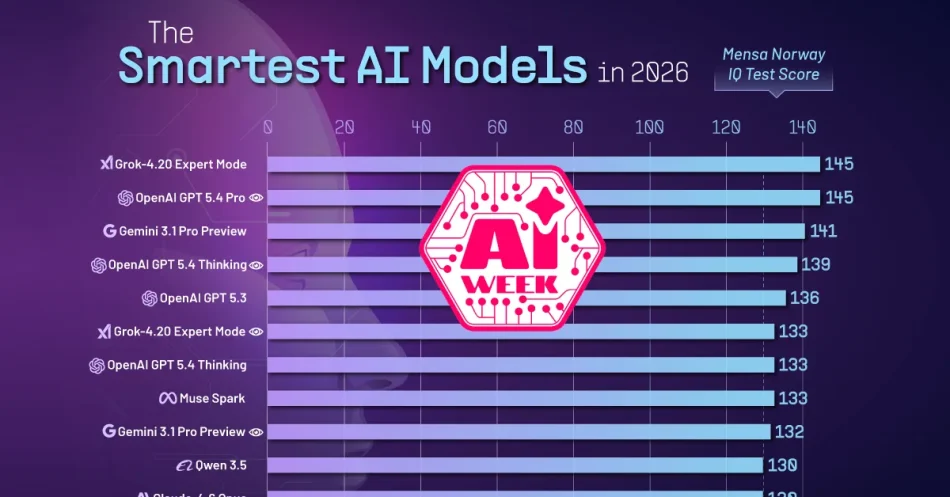
- Grok-4.20 Expert Mode and OpenAI GPT 5.4 Pro (Vision) are tied for the highest score, both achieving a Mensa Norway IQ of 145.
- The competition at the top is becoming increasingly close, with several models separated by only a few points.
- Scores have significantly increased compared to 2025, indicating rapid advancements in AI reasoning capabilities.
A Tie at the Top
The latest rankings provide a snapshot of how leading AI models perform on abstract pattern-recognition tasks. The table below summarizes the top models and their corresponding IQ scores:
| Model | Mensa Norway IQ (April 2026) |
|---|---|
| Grok-4.20 Expert Mode | 145 |
| OpenAI GPT 5.4 Pro (Vision) | 145 |
| Gemini 3.1 Pro Preview | 141 |
| OpenAI GPT 5.4 Thinking (Vision) | 139 |
| OpenAI GPT 5.3 | 136 |
| Grok-4.20 Expert Mode (Vision) | 133 |
| OpenAI GPT 5.4 Thinking | 133 |
| Meta Muse Spark | 133 |
| Gemini 3.1 Pro Preview (Vision) | 132 |
| Qwen 3.5 | 130 |
| Claude-4.6 Opus | 130 |
| Kimi K2.5 | 127 |
| Manus | 115 |
| DeepSeek R1 | 112 |
| DeepSeek V3 | 111 |
| Gemini 3.1 Flash Preview | 110 |
| Llama 4 Maverick | 110 |
| OpenAI GPT 5.3 (Vision) | 109 |
| Claude-4.6 Sonnet | 106 |
| Bing Copilot | 101 |
| Perplexity | 97 |
| Mistral Medium 3.1 | 96 |
| Claude-4.6 Sonnet (Vision) | 94 |
| Claude-4.6 Opus (Vision) | 82 |
| Llama 4 Maverick (Vision) | 79 |
| OpenAI GPT 5.4 Pro | 73 |
Insights from the Rankings
The results from the Mensa Norway IQ test indicate that the top models are converging in their capabilities. Grok-4.20 Expert Mode and OpenAI GPT 5.4 Pro (Vision) both achieving a score of 145 is a significant milestone. The narrow gap between the top contenders suggests that advancements in AI technology are accelerating, with improvements in reasoning and visual pattern recognition.
In comparison to last year, where the highest score was 135, the current scores reflect a remarkable leap forward in AI performance. This rapid development raises questions about the future trajectory of AI models and their potential applications across various sectors.
How TrackingAI Conducts the Test
TrackingAI utilizes the public Mensa Norway test, which consists of 35 visual-pattern puzzles. For models that do not process visual information, the questions are verbalized, while vision-capable models receive the original images directly. This approach allows for a comparative analysis of reasoning performance among different AI systems.
It is important to note that these results serve as a benchmark comparison rather than a definitive measure of overall intelligence. The visual nature of the test means that model scores can fluctuate based on how the questions are presented.
The Importance of This Benchmark
The TrackingAI leaderboard provides a straightforward way to compare reasoning performance over time. The methodology includes asking models the same question up to ten times if they refuse to answer, with the most recent response being used for scoring. However, it is crucial to recognize that an IQ-style benchmark only captures a fraction of an AI model’s capabilities. It does not assess other essential factors such as coding


